Wan 2.2 は WAN AI がリリースした新世代のマルチモーダル生成モデルです。このモデルは革新的な MoE(Mixture of Experts)アーキテクチャを採用しており、高ノイズと低ノイズのエキスパートモデルで構成されています。ノイズ除去タイムステップに応じてエキスパートモデルを分割できるため、より高品質な動画コンテンツを生成できます。
Wan 2.2 には 3 つのコア機能があります:映画レベルの美学制御で、専門的な映画産業の美学基準を深く統合し、照明、色彩、構図などの多次元視覚制御をサポートします。大規模複雑モーションで、様々な複雑な動きを簡単に再現し、動きの滑らかさと制御性を強化します。正確なセマンティック準拠で、複雑なシーンやマルチオブジェクト生成に優れ、ユーザーのクリエイティブな意図をより良く再現します。
このモデルはテキストから動画、画像から動画などの複数の生成モードをサポートし、コンテンツ作成、芸術創作、教育トレーニングなどのアプリケーションシナリオに適しています。
Wan2.2 プロンプトガイド
モデルのハイライト
- 映画レベルの美学制御:専門的なカメラ言語、照明、色彩、構図などの多次元視覚制御をサポート
- 大規模複雑モーション:様々な複雑な動きを滑らかに再現、動きの制御性と自然さを強化
- 正確なセマンティック準拠:複雑なシーンの理解、マルチオブジェクト生成、クリエイティブな意図をより良く再現
- 効率的な圧縮技術:5B バージョンの高圧縮率 VAE、メモリ最適化、混合トレーニングをサポート
Wan2.2 オープンソースモデルバージョン
Wan2.2 シリーズモデルは Apache 2.0 オープンソースライセンスに基づいており、商用利用をサポートしています。Apache 2.0 ライセンスは、元の著作権表示とライセンステキストを保持する限り、これらのモデルを商用目的を含めて自由に使用、修正、配布することを許可しています。| モデルタイプ | モデル名 | パラメータ | 主な機能 | モデルリポジトリ |
|---|---|---|---|---|
| ハイブリッドモデル | Wan2.2-TI2V-5B | 5B | テキストから動画と画像から動画の両方をサポートするハイブリッドバージョン、単一モデルで 2 つのコアタスク要件を満たす | 🤗 Wan2.2-TI2V-5B |
| 画像から動画 | Wan2.2-I2V-A14B | 14B | 静止画像を動的動画に変換、コンテンツの一貫性と滑らかな動的プロセスを維持 | 🤗 Wan2.2-I2V-A14B |
| テキストから動画 | Wan2.2-T2V-A14B | 14B | テキスト説明から高品質な動画を生成、映画レベルの美学制御と正確なセマンティック準拠を備える | 🤗 Wan2.2-T2V-A14B |
ComfyOrg Wan2.2 ライブストリーム
ComfyUI Wan2.2 の使用方法について、ライブストリームを実施しました。視聴して使用方法を学ぶことができます。
このチュートリアルでは 🤗 Comfy-Org/Wan_2.2_ComfyUI_Repackaged バージョンを使用します。
Wan2.2 TI2V 5B ハイブリッドバージョンワークフロー例
1. ワークフローファイルのダウンロード
ComfyUI を最新バージョンに更新し、メニューWorkflow -> Browse Templates -> Video から「Wan2.2 5B video generation」を見つけてワークフローを読み込んでください。
JSON ワークフローファイルをダウンロード
Run on Comfy Cloud
2. モデルの手動ダウンロード
Diffusion Model VAE Text Encoder3. 手順に従う
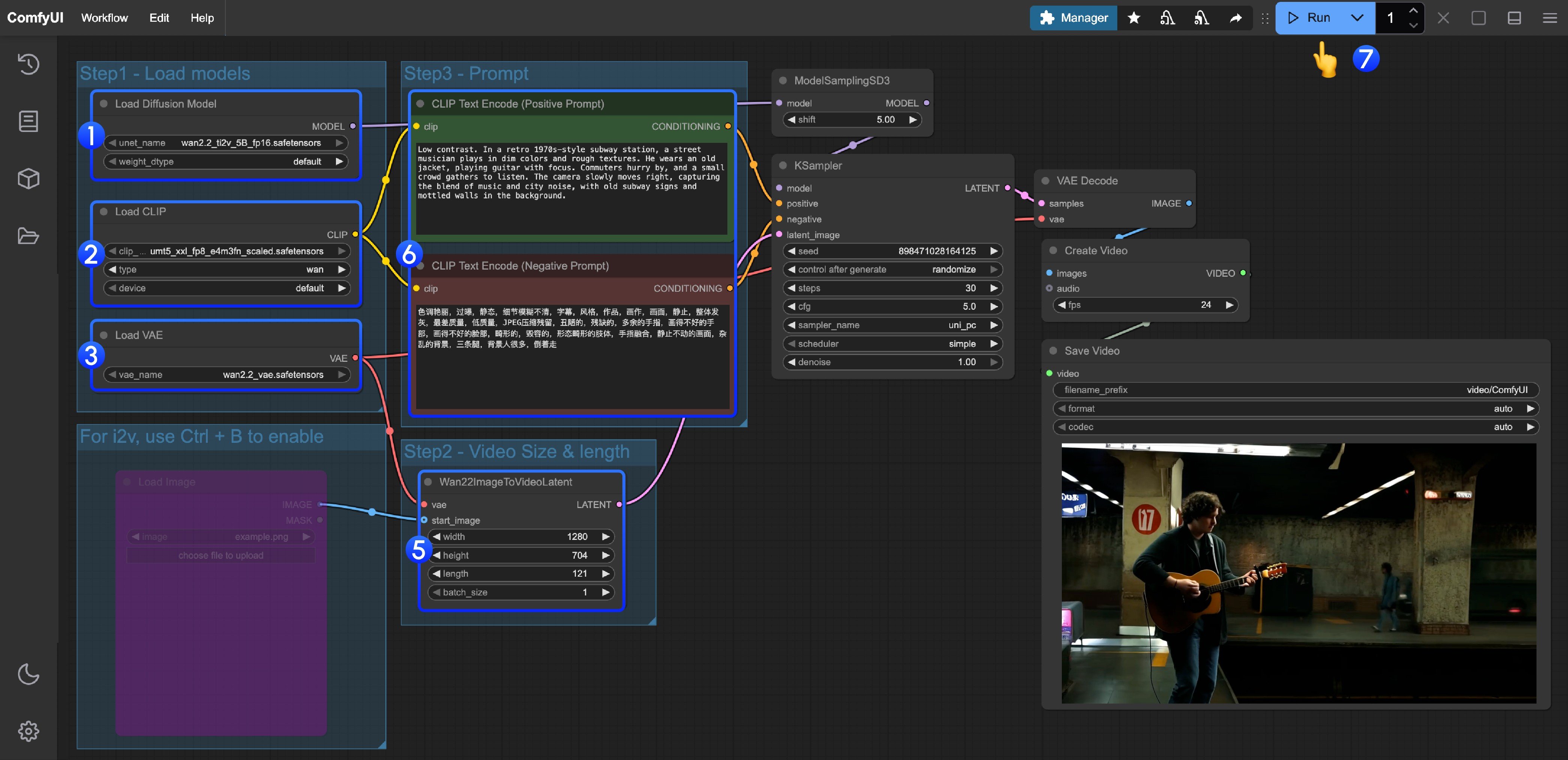
Load Diffusion Modelノードがwan2.2_ti2v_5B_fp16.safetensorsモデルを読み込んでいることを確認してください。Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルを読み込んでいることを確認してください。Load VAEノードがwan2.2_vae.safetensorsモデルを読み込んでいることを確認してください。- (オプション)画像から動画の生成を行う必要がある場合は、ショートカット Ctrl+B を使用して
Load imageノードを有効にし、画像をアップロードできます。 - (オプション)
Wan22ImageToVideoLatentノードで、サイズ設定と動画の総フレーム数(length)を調整できます。 - (オプション)プロンプト(ポジティブおよびネガティブ)を変更する必要がある場合は、手順 5 の
CLIP Text Encoderノードで変更してください。 Runボタンをクリックするか、ショートカットCtrl(cmd) + Enterを使用して動画生成を実行してください。
Wan2.2 14B T2V テキストから動画ワークフロー例
1. ワークフローファイル
ComfyUI を最新バージョンに更新し、メニューWorkflow -> Browse Templates -> Video から「Wan2.2 14B T2V」を見つけてワークフローを読み込んでください。
または、ComfyUI を最新バージョンに更新した後、以下の動画をダウンロードして ComfyUI にドラッグし、ワークフローを読み込んでください。
JSON ワークフローファイルをダウンロード
Run on Comfy Cloud
2. モデルの手動ダウンロード
Diffusion Model VAE Text Encoder3. 手順に従う
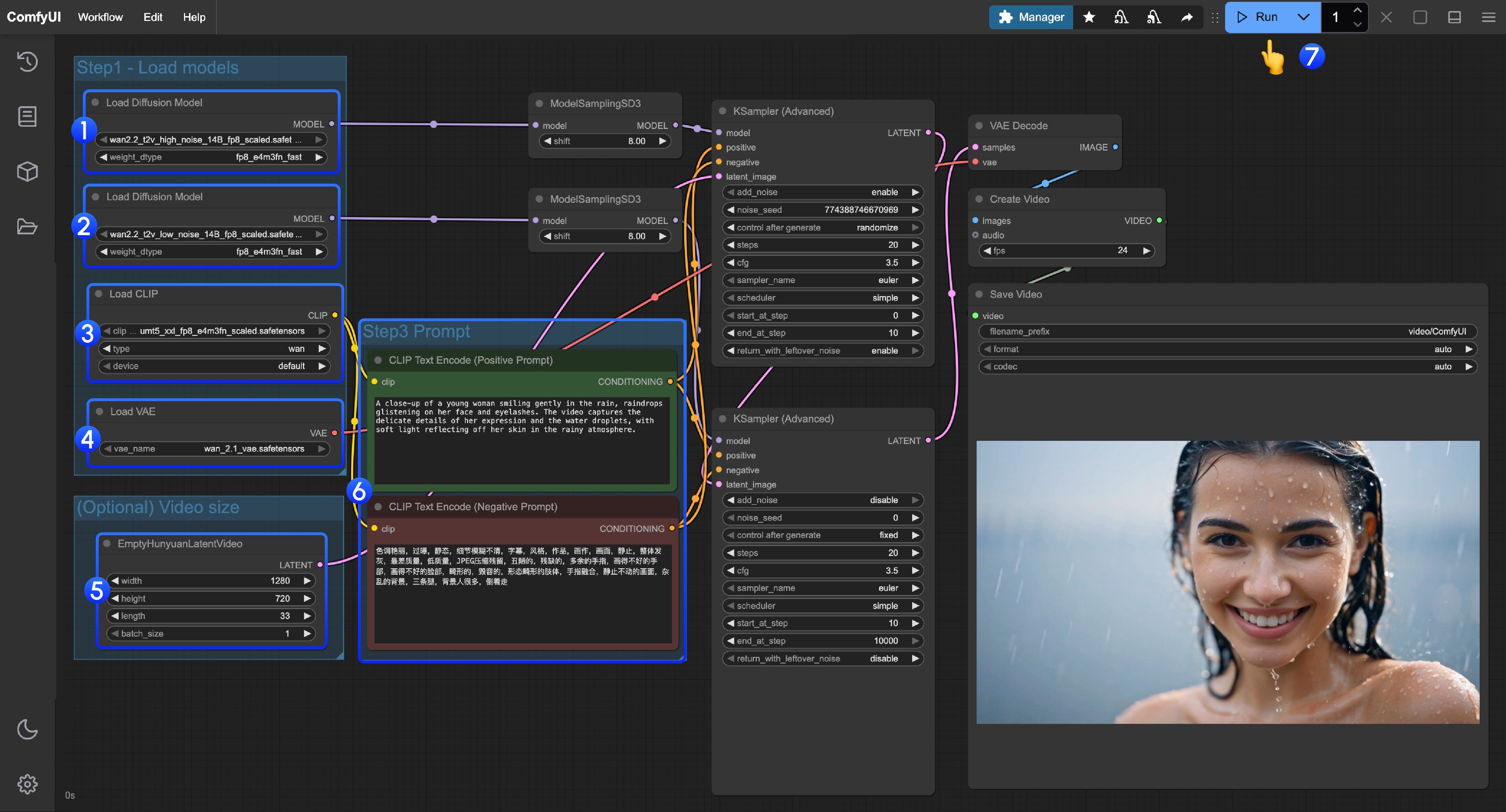
- 最初の
Load Diffusion Modelノードがwan2.2_t2v_high_noise_14B_fp8_scaled.safetensorsモデルを読み込んでいることを確認してください。 - 2 番目の
Load Diffusion Modelノードがwan2.2_t2v_low_noise_14B_fp8_scaled.safetensorsモデルを読み込んでいることを確認してください。 Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルを読み込んでいることを確認してください。Load VAEノードがwan_2.1_vae.safetensorsモデルを読み込んでいることを確認してください。- (オプション)
EmptyHunyuanLatentVideoノードで、サイズ設定と動画の総フレーム数(length)を調整できます。 - (オプション)プロンプト(ポジティブおよびネガティブ)を変更する必要がある場合は、手順 6 の
CLIP Text Encoderノードで変更してください。 Runボタンをクリックするか、ショートカットCtrl(cmd) + Enterを使用して動画生成を実行してください。
Wan2.2 14B I2V 画像から動画ワークフロー例
1. ワークフローファイル
ComfyUI を最新バージョンに更新し、メニューWorkflow -> Browse Templates -> Video から「Wan2.2 14B I2V」を見つけてワークフローを読み込んでください。
または、ComfyUI を最新バージョンに更新した後、以下の動画をダウンロードして ComfyUI にドラッグし、ワークフローを読み込んでください。
JSON ワークフローファイルをダウンロード
Run on Comfy Cloud
以下の画像を入力として使用できます:
2. モデルの手動ダウンロード
Diffusion Model VAE Text Encoder3. 手順に従う
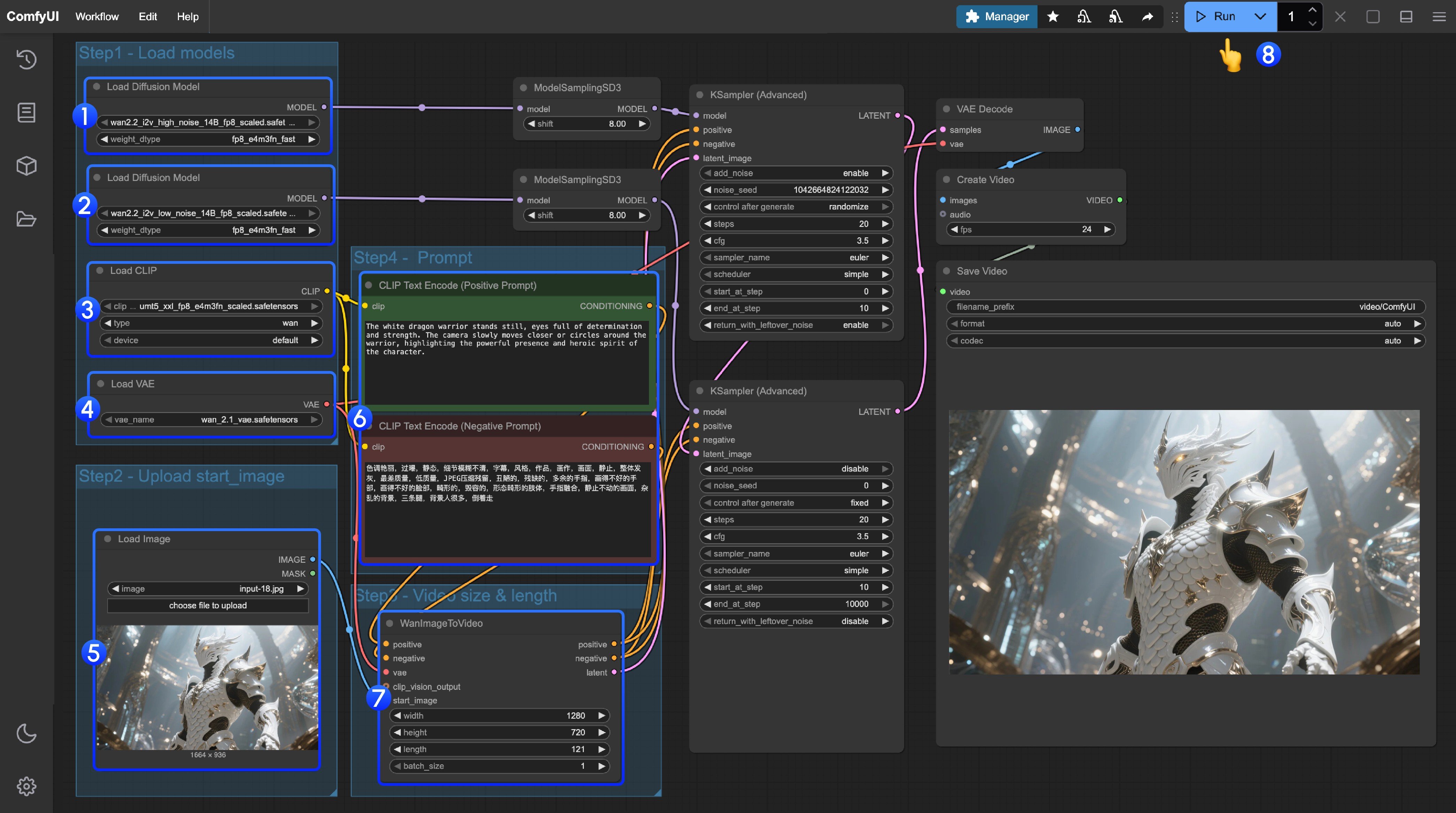
- 最初の
Load Diffusion Modelノードがwan2.2_t2v_high_noise_14B_fp8_scaled.safetensorsモデルを読み込んでいることを確認してください。 - 2 番目の
Load Diffusion Modelノードがwan2.2_t2v_low_noise_14B_fp8_scaled.safetensorsモデルを読み込んでいることを確認してください。 Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルを読み込んでいることを確認してください。Load VAEノードがwan_2.1_vae.safetensorsモデルを読み込んでいることを確認してください。Load Imageノードで、起始フレームとして使用する画像をアップロードしてください。- プロンプト(ポジティブおよびネガティブ)を変更する必要がある場合は、手順 6 の
CLIP Text Encoderノードで変更してください。 - (オプション)
EmptyHunyuanLatentVideoで、サイズ設定と動画の総フレーム数(length)を調整できます。 Runボタンをクリックするか、ショートカットCtrl(cmd) + Enterを使用して動画生成を実行してください。
Wan2.2 14B FLF2V ワークフロー例
最初と最後のフレームのワークフローは、I2V セクションと同じモデル場所を使用します。1. ワークフローと入力素材の準備
以下の動画または JSON ワークフローをダウンロードし、ComfyUI で開いてください。JSON ワークフローをダウンロード
Run on Comfy Cloud
以下の画像を入力素材としてダウンロードしてください:

2. 手順に従う
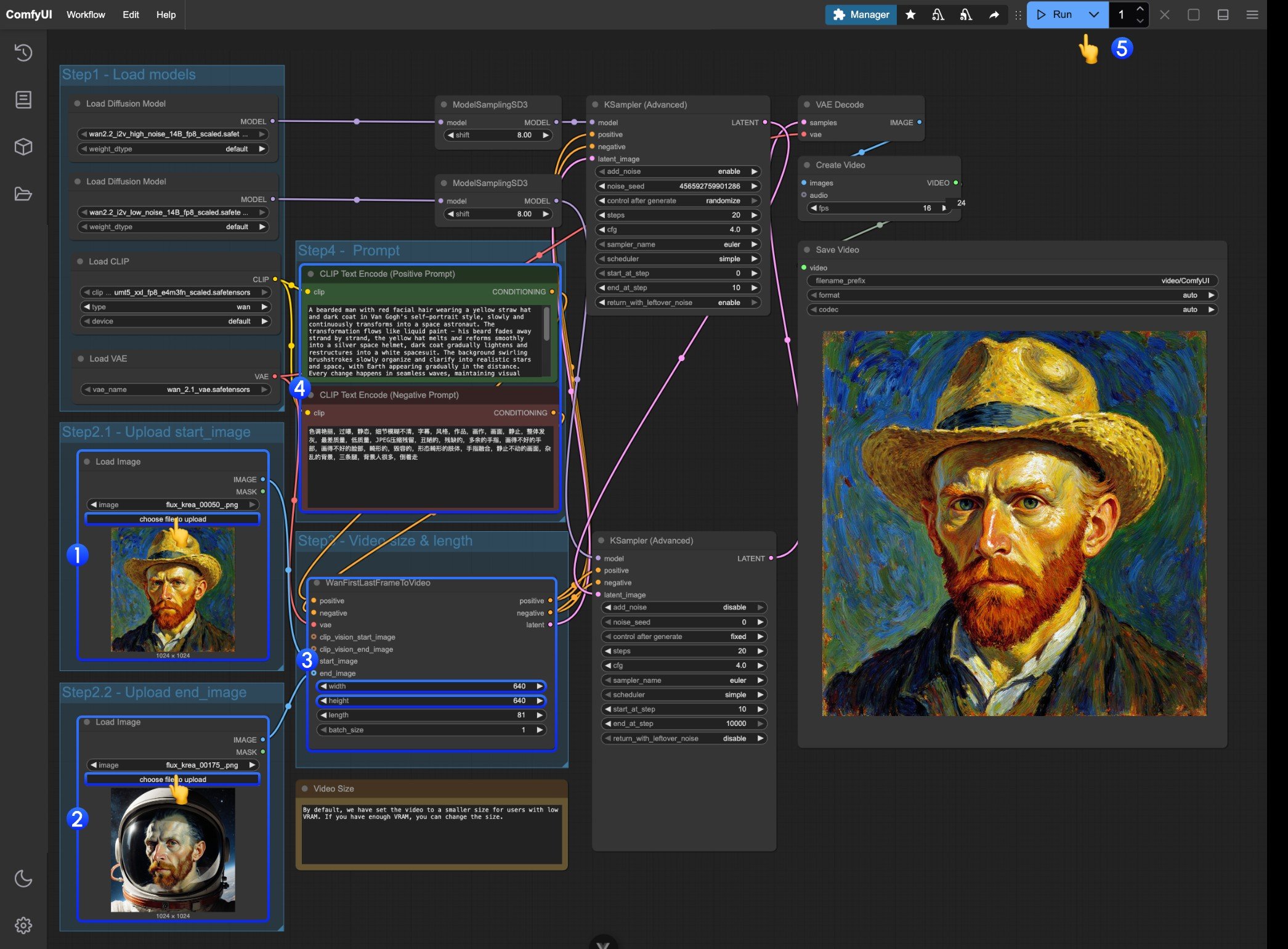
- 最初の
Load Imageノードで、起始フレームとして使用する画像をアップロードしてください。 - 2 番目の
Load Imageノードで、終了フレームとして使用する画像をアップロードしてください。 WanFirstLastFrameToVideoノードでサイズ設定を調整してください。- デフォルトでは、低 VRAM ユーザーがリソースを使いすぎないように、比較的小さいサイズが設定されています。
- 十分な VRAM がある場合は、720P 程度の解像度を試すことができます。
- 最初と最後のフレームに応じて、適切なプロンプトを作成してください。
Runボタンをクリックするか、ショートカットCtrl(cmd) + Enterを使用して動画生成を実行してください。